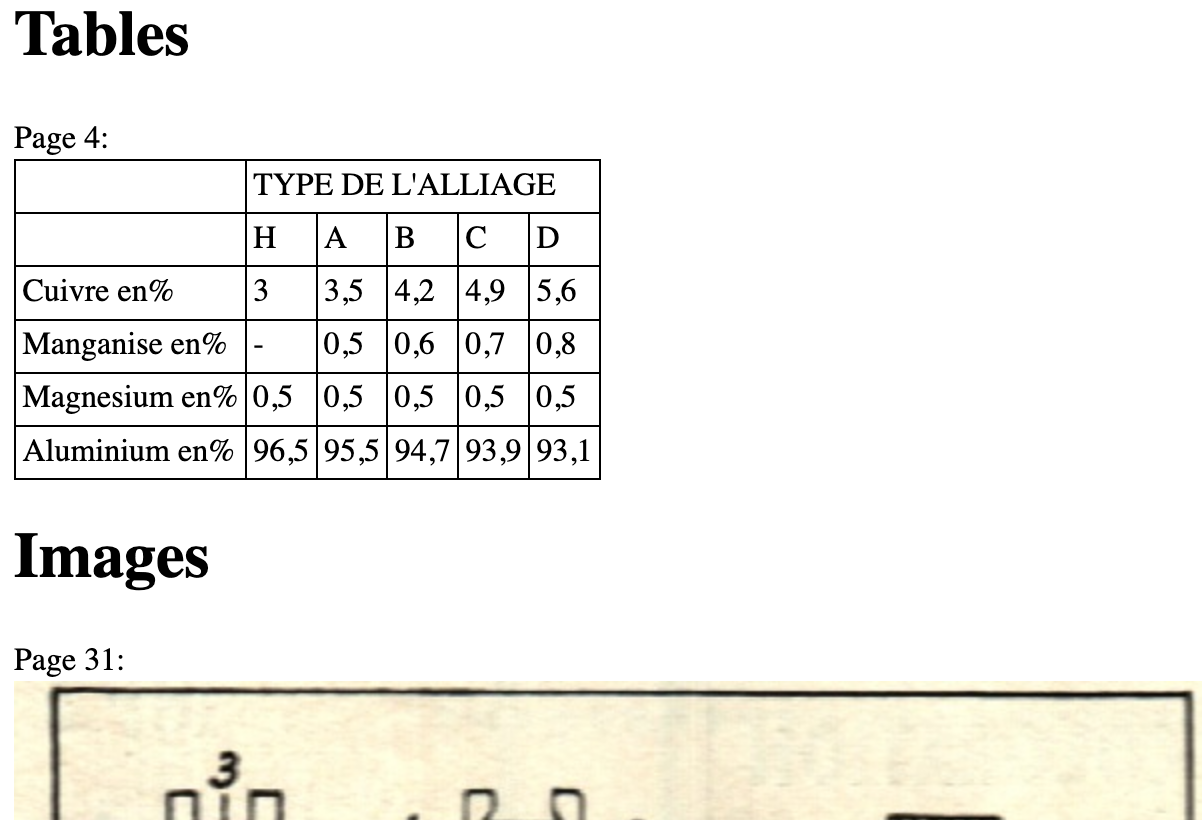
analyzing loosely-structured documents
Providing efficient interfaces for subject specialists to identify and organize key facts from unstructured texts is a long-standing problem with which progress towards routine solutions has been slow. Automated approaches are frustrated by irregularity of documents and imperfect recognition of print by existing software, and useful 'understanding' of corpora still requires human judgement based on subject and domain experience.
This project addresses the extraction at scale of key scientific facts from documents, in a range of formats, published from the early 20th century onwards.

preserving annotation
Accurately tokenizing specific 'snippets' of text with easy-to-use workflows enables compilation of key facts based on schemata, and efficient generation of agnostic data for a range of analysis software.
Retaining connection with annotations using persistent identifiers (PIDs) means that processed data can subsequently be linked interactively with the context where the page fragment originated.
Time-stamps and contributor identifiers (ORCID) are temporarily managed by annotation stores, then standards-based Annotation Collections are generated for analysis and repository use—making investment in annotation findable and preservable.
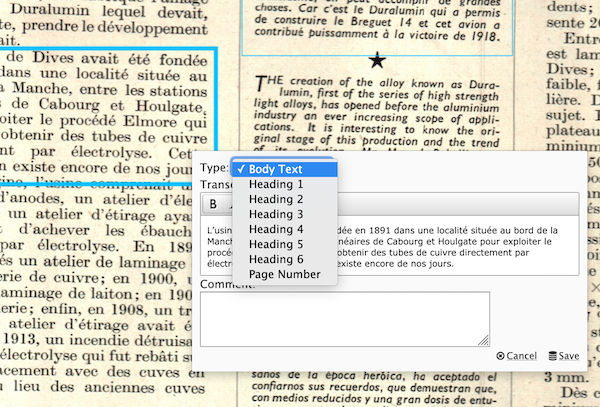
tailoring annotation workflows to research activities
Direct support of research activity-specific metadata vocabularies, as well as significant efficiency benefits for contributors, is possible by tailoring out-of-the-box functionality for creating annotations in IIIF applications such as Mirador.
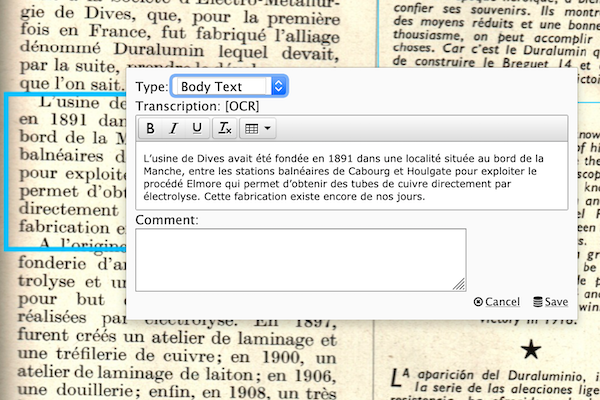
correct automated tokenization immediately annotation is created
Multiple 'comment' and 'transcription' contexts can be provided and task-specific check-boxes, as well as OCR and tokenization tools.

managing annotation workflows
Visualization of annotation work-in-progress, as well as generating interim data-sets for preliminary analysis, are valuable productivity tools.
Here, links to dynamically-generated HTML renders and TSV datasets have been configured within Mirador.
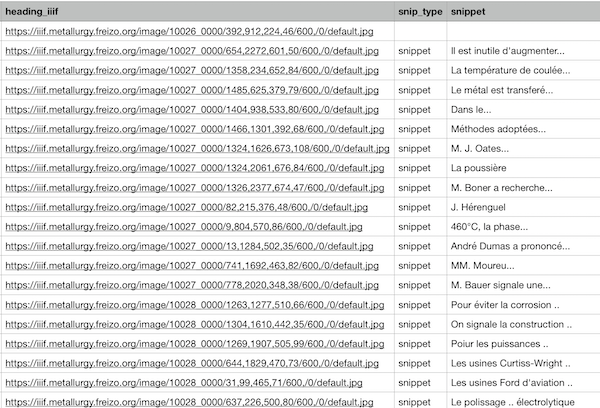
interactive generation of data-sets
Opening immediately in a spreadsheet application or output using formats such as TSV, current progress can readily consumed by external applications such as data-bases.

interactive HTML rendering
Portable HTML by-products can be generated in-band, in multiple variants, for immediate use by external applications and for rapid checking or monitoring of a team of contributors.
Multiple annotation passes—potentially a mix of machine and manual work—can build on successive activities to achieve complex extraction in large print corpora:
- create structure, such as a hierarchy of nested headings or sections, enabling automated generation of tables of contents
- identify and transcribe snippets or paragraphs—generating agnostic HTML for styling
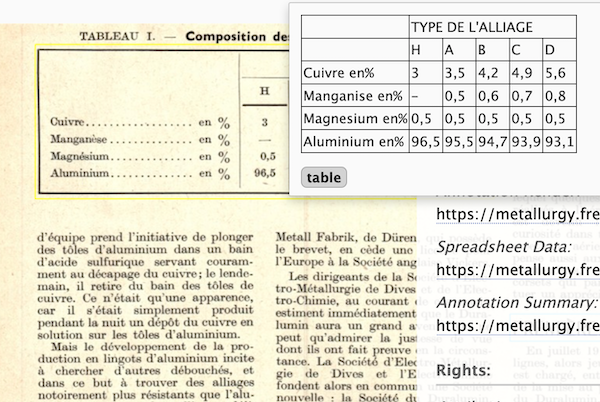
- capture tabluated data
- provide IIIF page fragments to external workflows and applications
research workflows
These slides summarise a research workflow—either for redelivery of existing research data to Trusted repositories tocomply with FAIR principles, or for development of new sustainable research activities by our partners. Data Futures can process a wide range of source data formats and generate Invenio and other repositories and databases, as well as Zenodo deposits, as output. It maintains data resources for partners in multiple domains from engineering to the humanities, life and physical sciences.

Scientific Annotation
Annotation of research data using embedded and stand-off annotation techniques is a long-standing source of metadata, but as part of ongoing research investment it has been difficult to make shareable or to preserve effectively. Since 2015 Data Futures has worked on redelivery of annotated corpora—which often use legacy or proprietary annotation technologies or hybrid and paper-based methods—to create new data resources based on Trusted repository and W3C Web Annotation Data Model (WADM) annotation technologies.
Annotations as Primary Research Assets
Standards-based scientific annotation, using WADM, together with Persistent IDentifiers (PIDs) and ORiginal Contributor IDentifiers (ORCID) enable robust preservation and sharing of annotated corpora and also effective discovery, sharing and re-use of annotations. Many of the research project case studies and repositories presented on this site address annotation made into primary research assets in their own right—accessible in Invenio repositories via Elasticsearch.