
building a corpus of historic international treaties and regulations
During spring 2020 a collaborative annotation task was carried out by the Institute for European Global Studies (EIB), Basel University and a team at Hesburgh Libraries, Notre Dame University, IN USA, with contribution from ENS-Lyon.
Publication sections from EIB‘s Asian Directory & Chronicle digital corpus were annotated to identify treaty documents, and these were then analyzed to build an Invenio repository of the multiple instances of canonical treaties.

multiple instances of the same document
Multiple challenges: determining the number of unique documents in this corpus of publications—covering half a century, having 1000s of pages annually, and without tables of contents. Editorial decisions determined which treaties were selected for publication. Which treaty parties were envolved? Which documents were published for how many years? How often were they updated?
To understand the way the publication organizes treaties we need to identify and curate multiple instances of the same document.
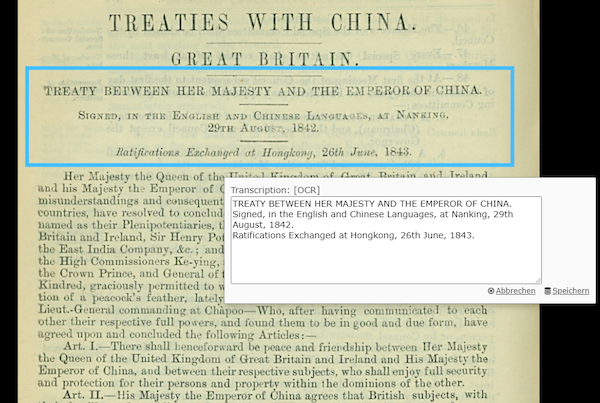
manual annotation with OCR support
Three phase approach to i) identify treaties sections in each publication, ii) identify titles of documents on those manifests and iii) normalize and classify documents (treaty instances), relating multiple versions to canonical treaties.
In phase one page ranges of the treaty sections were identified by EIB; creating new IIIF manifests covering 33 years between 1863 and 1934. A new task is planned to process the remaining 30 years.
Section headings were annotated by an international group of contributors managed by Notre Dame's Hesburgh Libraries in phase three. Contributors working on the annotation task were provided instruction documents and a virtual support desk but they received no other training. Quality-checking was subsequently carried out by EIB.
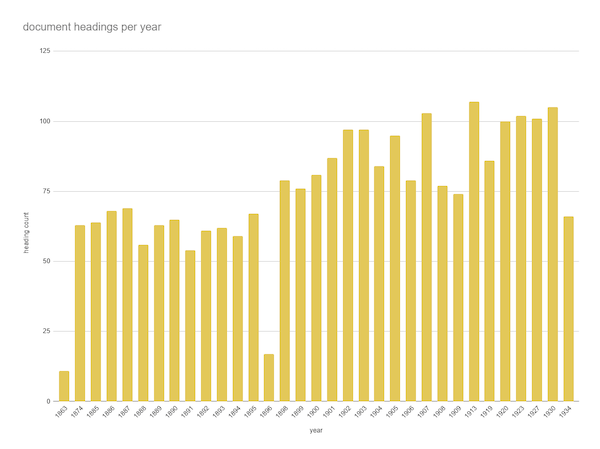
refining annotation output
More than 2400 headings were detected. Due to errors in print and OCR, as well as changing naming conventions in the corpus and segmentation decisions made by annotators, the degree of variations in titles describing the same document is high.
Up to 27 variations of the same document title were found.
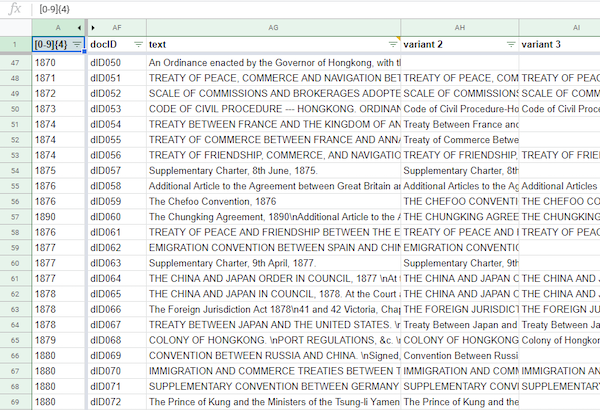
normalization of document titles
Rapid prototyping of normalization in a spreadsheet: variations of the same document title were clustered and a local document identifier added.
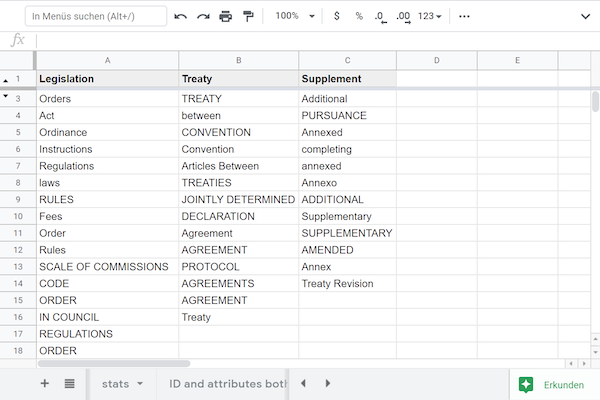
additional classification and relations
Dictionary-based prediction was developed to classify document type and the signatories; extraction of date of signature was done using spreadsheet regular expressions.
Predicted values and the creation of relations between documents was validated manually.
automated generation of Invenio repository from annotations
Invenio-3.3 repository https://adc-treaties.unibas.hasdai.org/ generated from the processed annotation metadata contains approximately 2500 instances of treaties and regulations mapped to less than 400 canonical documents.
search facets:
- parties
- year published in the Directories and Chronicles
- year signed
- document type

Invenio metadata created from annotations
canonical document
- record ID
- document ID
- canonical title
- parties
- is-related-to
- is-supplement-of
document instances
- link to starting page in book
- transcribed title
- instance ID
- year published by Directories and Chronicles
- IIIF fragment URL
- contributor (name, ORCID, timestamp)
research workflows
These slides summarise a research workflow—either for redelivery of existing research data to Trusted repositories tocomply with FAIR principles, or for development of new sustainable research activities by our partners. Data Futures can process a wide range of source data formats and generate Invenio and other repositories and databases, as well as Zenodo deposits, as output. It maintains data resources for partners in multiple domains from engineering to the humanities, life and physical sciences.

Scientific Annotation
Annotation of research data using embedded and stand-off annotation techniques is a long-standing source of metadata, but as part of ongoing research investment it has been difficult to make shareable or to preserve effectively. Since 2015 Data Futures has worked on redelivery of annotated corpora—which often use legacy or proprietary annotation technologies or hybrid and paper-based methods—to create new data resources based on Trusted repository and W3C Web Annotation Data Model (WADM) annotation technologies.
Annotations as Primary Research Assets
Standards-based scientific annotation, using WADM, together with Persistent IDentifiers (PIDs) and ORiginal Contributor IDentifiers (ORCID) enable robust preservation and sharing of annotated corpora and also effective discovery, sharing and re-use of annotations. Many of the research project case studies and repositories presented on this site address annotation made into primary research assets in their own right—accessible in Invenio repositories via Elasticsearch.